The mrcc project’s homepage is here: mrcc project.
Abstract
Table of Contents
mrcc is an open source compilation system that uses MapReduce to distribute C code compilation across the servers of the cloud computing platform. mrcc is built to use Hadoop by default, but it is easy to port it to other could computing platforms, such as MRlite, by only changing the interface to the platform. The mrcc project homepage is http://www.ericzma.com/projects/mrcc/ and the source code is public available.
Introduction
Compiling a big project such as Linux may cost much time. Usually, a big project consists of many small source code files and many of these source files can be compiled simultaneously. Parallel compilation on distributed servers is a way to accelerate the compilation.
In this project, we build a compilation system on top of MapReduce for distributed compilation.
Design and architecture
The system of mrcc consists of one master server that controls the job and many slave servers that do the compilation work as shown in Figure 1. The master and the slaves can be one of the jobtracker or the tasktracker of the MapReduce system.
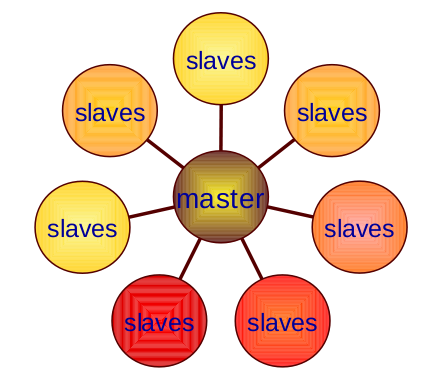
Figure 1: The architecture of mrcc
mrcc runs as a front end of cc. When compiling one project, the user only need to add “-jN” parameter and “CC=mrcc” at the end of the normal “make” arguments and make the project on the master server. make will build a dependency tree of the project source files and then fork multiple mrcc instances when several source files can be compiled in parallel.
mrcc will first do preprocessing such as expanding the options and inserting the header files into the source file. Then mrcc will determines whether the job can be done on MapReduce depending on the compiler’s options. For ensuring the correctness of the compilation, mrcc only distributes the jobs to slaves when they are safe. The other jobs are done on the master server locally.
When doing remote compilation, mrcc first put the preprocessed source file into the network file system which is HDFS when using Hadoop, then it runs the job on MapReduce. Only the mapper which is called mrcc-map is used in this system. mrcc-map first gets the source file from the network file system, and then it calls the compiler locally on the slave. After the compilation finished, mrcc-map puts the object file which is the result of the compilation back into the network file system. After mrcc-map finished, mrcc on the master server get the object file from network file system and puts it into the local file system on the master node. By now, the compilation of one source file is finished. make can go on to compile the other files that depends on the completed one.
Implementation
The mrcc compilation system consists of two core parts: the main program mrcc and the mapper for MapReduce called mrcc-map.
The overall system consists of seven parts:
- The main program mrcc (mrcc.c, compile.c, remote.c, safeguard.c, exec.c);
- The mapper mrcc-map (mrcc-map.c);
- The compiler options processing part (args.c);
- The logging part (trace.c, traceenv.c);
- The network file system and MapReduce interface part (netfsutils.c, mrutils.c);
- The temporary files cleaning up part (tempfile.c, cleanup.c);
- Some other utilities for processing string, file path and name, and I/O operation (utils.c, files.c, io.c).
In this report, we only introduce the two core parts of this system: mrcc and mrcc-map.
mrcc
The work flow is shown as Figure 2. There are five time lines in the process: mrcc is called, begins to compile locally or remotely while source file is being preprocessed, the preprocessing finishes, mrcc returns and mrcc finishes. During this process one or two new process is created by mrcc for source preprocessing or compiling. And some other works such as logging are done which we will not introduce. In the work flow graph, only the core functions are shown.
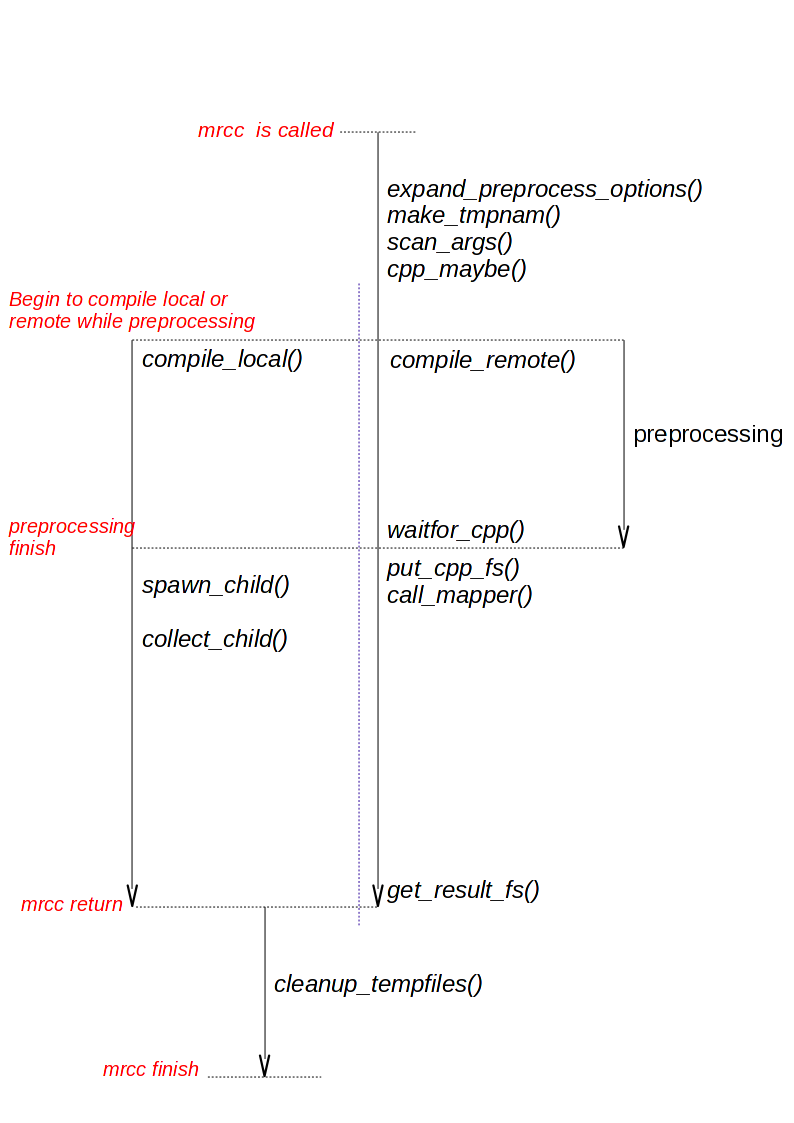
Figure 2: Work flow of mrcc
When mrcc is called, it first preprocesses the compiler options by functions such as expand_preprocessor_options() which expands the arguments passed to preprocessor. Then* make_tmpnam()* is called to creates a temporary file inside the temporary directory and registers it for later cleanup. In make_tmpnam() a random number is generated for the temporary file. We use this random number as the id of the job and the object file name. The temporary output directory of the MapReduce job will be generated from this id to avoid name conflict ion. For example, if the temporary file name for storing a preprocessed source file is “/tmp/mrcc_36994a30.i”, the object file name and the output directory name are “/tmp/mrcc_36994a30.o” and “/tmp/mrcc_36994a30.odir” on the network file system.
mrcc then scans the options to determine whether this job can be done on remote server by calling scan_args(). While scanning the arguments, mrcc should also determine the default output file name according to the input source name. It is a little hard because the cc option rules are pretty complex. After that, mrcc calls the cpp_maybe() function to fork another process to run the preprocessor. The preprocessor insert header files into the source file. So the compiler version on the master and slaves needn’t to be identical since the remote server needn’t to do preprocessing.
Then mrcc compiles the source remotely or locally depending on the compiler options. Local compilation is straight forward. mrcc wait for the preprocessor process to complete and fork another process to do the compilation.
If the source file can be compiled on remote server, mrcc calls the function compile_remote(). mrcc should first wait for preprocessor to complete. Then mrcc put the preprocessed file into the network file system. After that, mrcc calls call_mapper() to generate relevant options and arguments from the id of the temporary file and the options and arguments of the compiler. The it runs the job on MapReduce. In this project, we use Hadoop Streaming to run the mrcc-map on the slaves. The options for mrcc-map are passed with the streaming job options.
After mrcc-map successfully finishes the job, the object file now exists on the network file system. mrcc generates the output file name from the id of the temporary file and calls get_result_fs() to retrieve the object file from the network file system.
As soon as mrcc gets the object file, it returns so that make can continue to compile other source files that may depend on the completed one. But there are still several temporary files and directories on the network file system and local disk that needed to be cleaned up. We use a tricky function atexit() to do the cleaning up work after mrcc returns. By using atexit() some of the clean up I/O operation are done while the next compilation is running to improve the overall performance.
mrcc-map
mrcc-map is put in local directories on all the slaves servers. We doing this to avoid distributing the mrcc-map when the job is called because the mrcc-map does not changed during compiling one project. The flow of mrcc-map is simpler than mrcc as shown in Figure 3.
mrcc-map first parse it’s arguments and finds out the file id generated by mrcc and the compilation options and arguments. Then mrcc-map gets the preprocessed file from net file system according to the id. After getting the preprocessed file, mrcc-map calls the local gcc/cc compiler and passes the compilation options and arguments to it. Then mrcc-map puts the object file to the netwrok file system and returns immediately. The clean up work is done after mrcc-map finishes to parallel I/O operation and the compilation in the same way that mrcc does.
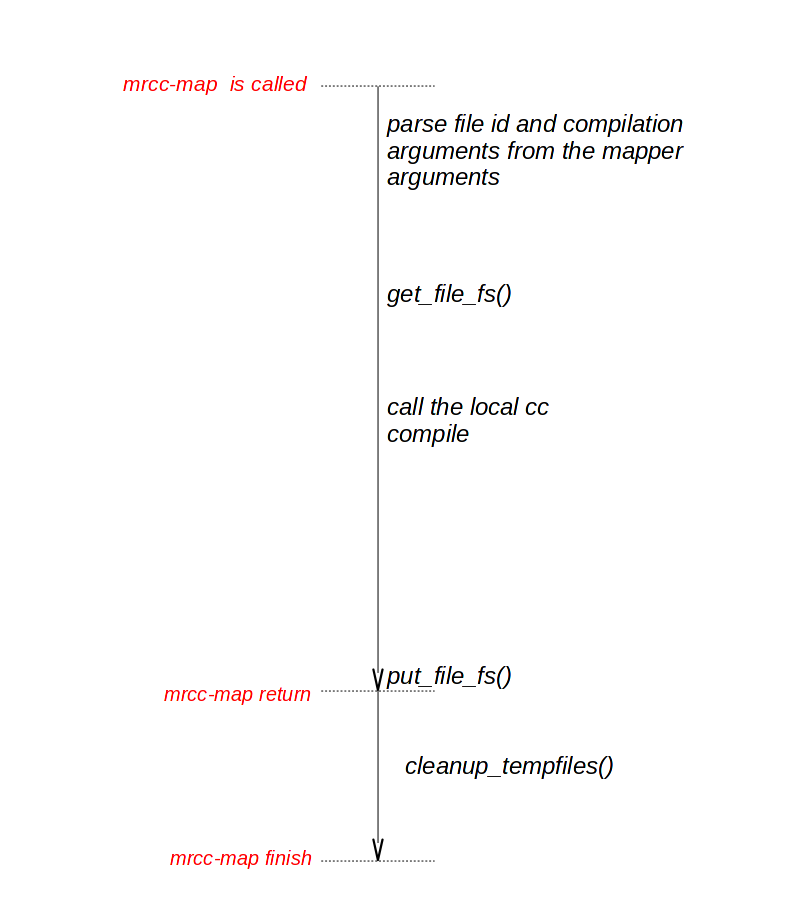
Figure 3: mrcc-map work flow
Evaluation
Please refer to this paper for the evaluation experiments and results:
Z. Ma and L. Gu.The Limitation of MapReduce: A Probing Case and a Lightweight Solution. In Proc. of the 1st Intl. Conf. on Cloud Computing, GRIDs, and Virtualization (CLOUD COMPUTING 2010). Nov. 21-26, 2010, Lisbon, Portugal. (PDF from one author’s homepage)
Installation and configuration
Install hadoop
Install Hadoop into a directory, such as /lhome/zma/hadoop and start Hadoop.
Please refer to this tutorial for how to install and start Hadoop:
Configuration
In netfsutils.c:
As an example, we assume hadoop command’s full path is: /lhome/zma/hadoop/bin/hadoop
Set the variables as follows (We use the full path to avoid bad PATH environment).
const char* put_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -put"; const char* get_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -get"; const char* del_file_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -rm"; const char* del_dir_fs_cmd = "/lhome/zma/hadoop/bin/hadoop dfs -rmr";
In mrutils.c
Set the variables and We also use the full path.
const char* mr_exec_cmd_prefix = "/lhome/zma/hadoop/bin/hadoop jar /lhome/zma/hadoop/contrib/streaming/hadoop-0.20.2-streaming.jar -mapper "; const char* mr_exec_cmd_mapper = "/home/zma/bin/mrcc-map "; const char* mr_exec_cmd_parameter = "-numReduceTasks 0 -input null -output ";
Compile and install:
$ make
# make install
How to use it
Compile the project using mrcc on MapReduce
As building a project:
$ make -j16 CC=mrcc
-jN: N is the maximum parallel compilation number. N may be set to the number of CPUs in the cluster.
Enable detailed logging if needed
On master node in the same shell where mrcc runs:
$ . docs/mrcc.export
Or set environment variables:
MRCC_LOG=./mrcc.log MRCC_VERBOSE=1 export MRCC_LOG export MRCC_VERBOSE
Related work
GNU make can execute many commands simultaneously by using “-j” option. But make can only execute many commands on local machine. mrcc makes use of this feature of make and distributed these commands (compilation) across servers on MapReduce.
distcc is a program to distribute compilation of C/C++/Objective code between several machines on a network. distcc must use a daemon on every slaves and the master must controls all the jobs details such as load balance and failure tolerance. distcc is easy to set up and fast in a cluster with a small amount of machines, but it will be hard to manage this system when distcc is running on a computing platform with thousands of machines.
References
- Dean, J. and Ghemawat, S. 2004. MapReduce: simplified data processing on large clusters. In Proceedings of the 6th Conference on Symposium on Operating Systems Design & Implementation – Volume 6 (San Francisco, CA, December 06 – 08, 2004).
- Hadoop project. http://hadoop.apache.org
- mrcc project. http://www.ericzma.com/projects/mrcc/
- Hadoop 0.20.1. http://hadoop.apache.org/common/releases.html#Download
- Linux. http://www.kernel.org/
- distcc project. https://github.com/distcc/distcc
- GNU make. http://www.gnu.org/software/make/
- Zhiqiang Ma and Lin Gu.The Limitation of MapReduce: A Probing Case and a Lightweight Solution. In Proc. of the 1st Intl. Conf. on Cloud Computing, GRIDs, and Virtualization (CLOUD COMPUTING 2010). Nov. 21-26, 2010, Lisbon, Portugal.
I posted a similar idea on my blog last year, although never implemented it –
http://craig-henderson.blogspot.com/2009/09/distributed-compilation-using-mapreduce.html
Data distribution is often a barrier to using massively parallel processing. Nice post
— Craig
@Craig Thanks!
A more efficient way to distribute data will help a lot. I find that starting a job on Hadoop is also too slow (about 20s) for compilation.
Hadoop is designed for processing large amount of data. 20s is okay for a big job. But it is too much for compiling one source file.
The performance evaluation uses 4 VMs, rather than 4 physical machines. I think it’s misleading to say that the performance of mrcc was worse on 4 servers than gcc on 1 server when you were really using just one server in both cases, and just adding a bunch of overhead with VMs.
@John Doe
It is true that the 4 VMs on one physical machine is different from 4 physical machines. The main difference may come from the I/O performance. But I have done some other experiments that show that the result here is very similar with using 4 physical machines:
1. I compiled four copies of the same Linux kernel simultaneously on these 4 VMs. All these 4 VMs took ~60min to finish.
2. Avoiding I/O operation by putting all files into memory (I can see from Xen that the slaves don’t have I/O operation). The result is that it is faster but still very slow.
Another reason is that the VMs are running on top of Xen. Every VM has 2 VCPU while the physical machine has 16 (thanks to HT) ones. I have also done some simple experiments of Xen’s performance:
a-simple-cpu-and-memory-performance-test-of-xen-dom0-and-domu
I use 4 VMs mainly because that I can not find 4 machines that are so similar to each other. Any further experiment of mrcc is warmly welcomed :) All source code of mrcc can be found from http://fclose.com/p/mrcc/
Hi, Can I compile and test my helloworld device driver in any known remote linux server. If it is possible, then can you please provide me link.
I am a newbie in linux. I want to compile my helloworld device driver in any linux system(say fedora). But as of now, I just want to compile and run this test driver. I will be downloading kernal source and compile in my system also sometime later.
@abhi
I don’t have experience of writing Linux driver. But I find a article that introduce it:
http://www.freesoftwaremagazine.com/articles/drivers_linux
Hope it can help you.